
티스토리 뷰
정렬 알고리즘
선택정렬이란?
- 실제 프로그래밍에서 많이 사용되는 간단한 정렬방법으로 오름차순을 기준으로 한다면,
최소값을 찾아 왼쪽으로 이동시키는데 배열크기만큼 반복하여 정렬하는 방법이다.
- 가장 작은 값을 찾아서 첫번째 위치에 있는 값과 교환하고, 두번째로 작은 값을 찾아 두번째
위치에 있는 값과 교환하는 방법으로 이러한 방법을 반복한다.
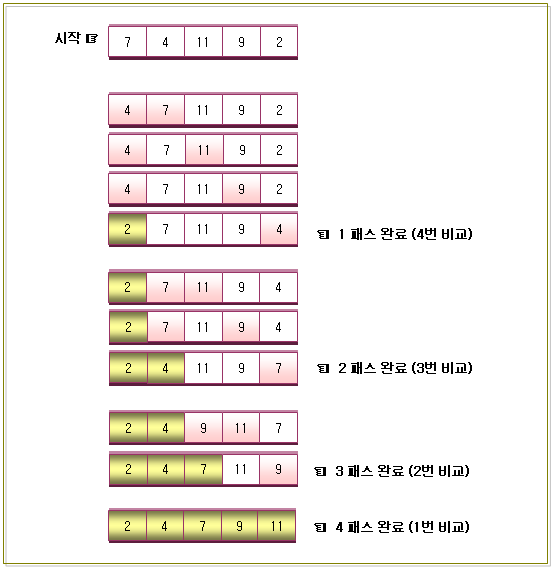
- 최선일 경우의 비교회수 공식 : N - 1
- 최악일 경우의 비교회수 공식 : N(N – 1)/2
- 위의 그림을 보시면 아시겠지만 제일 처음에는 (N – 1)번을 비교하고,
그 다음에는 (N – 2)번 만큼 비교하고, 그 다음은 (N – 3)번을 비교하면서 비교회수가 1이 될
때까지 이 작업을 반복할 것이다.
- 비교회수는 (N – 1) + (N – 2) + (N – 3) …… + 1 이 될 것이다.
최대 (N – 1)번을 수행할 것이며, 각 패스가 수행할 때마다
2) 선택정렬의 연산시간
-. 연산시간 공식 : O(n²)
-. 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
3) 선택정렬의 장점
-. 데이터의 양이 적을 때 아주 좋은 성능을 나타낸다.
-. 작은 값을 선택하기 위해서 비교는 여러 번 하지만 교환횟수가 작다
4) 선택정렬의 단점
-. 가장 작은 값과 현재값을 교환하는 방식이라 현재값이 뒤쪽의 어디로 갈지 알 수 없으므로
안전성이 없다.
-. 100개 이상의 자료에 대해서는 속도가 급격히 떨어져서 적절히 사용되기가 힘들다.
| 삽입 정렬 알고리즘 |
1. 삽입정렬(Insert Sort)이란?
-. 가장 왼쪽에 있는 첫번째 값을 이미 정렬된 상태로 가정하고 나머지 자료들을 정렬한다.
-. 두번째 값을 기준으로 첫번째 값을 비교하여 값에 따라 순서대로 나열하며, 세번째 값을
기준으로 두번째 값과 첫번째 값을 비교하여 값에 따라 순서대로 나열한다.
위와 같은 방법으로 n - 1개의 값과 비교하여 삽입될 적당한 위치를 찾아 삽입한다.
-. 이미 정렬이 된 부분에 새로운 값을 적절한 순서에 삽입하는 동작을 반복적으로 하는 정렬이다.
-. 적은 비교와 많은 교환이 필요한 방법이므로 소량의 자료를 처리하는데 가장 유리한다.
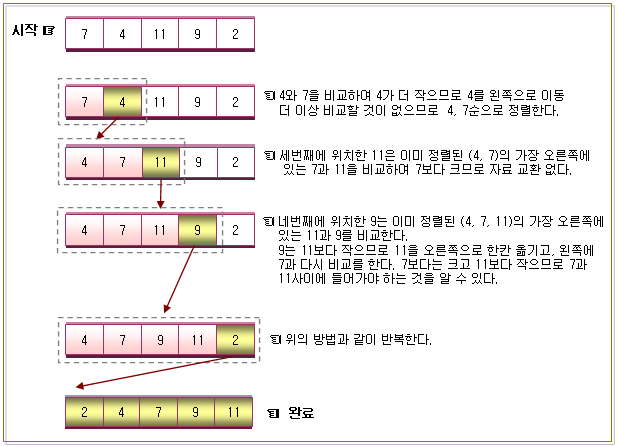
3. 삽입정렬의 비교회수
-. 최선일 경우의 비교회수 공식 : N - 1
-. 최악일 경우의 비교회수 공식 : N(N – 1)/2
-. 위의 그림을 보시면 아시겠지만 제일 처음에는 (N – 1)번을 비교하고,
그 다음에는 (N – 2)번 만큼 비교하고, 그 다음은 (N – 3)번을 비교하면서 비교회수가 1이 될
때까지 이 작업을 반복할 것이다.
-. 비교회수는 (N – 1) + (N – 2) + (N – 3) …… + 1 이 될 것이다.
최대 (N – 1)번을 수행할 것이며, 각 패스가 수행할 때마다
수학식으로 표현하면 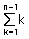 이므로 공식은 N(N – 1)/2 이런 공식이 성립된다.
이므로 공식은 N(N – 1)/2 이런 공식이 성립된다.
-. 5개의 값을 오름차순으로 선택정렬을 하면
공식에 의해서 5(5 – 1)/2 = 10 가 성립된다.
즉, 총 10번의 비교를 통해서 오름차순으로 정렬된 값을 볼 수 있다.
4. 삽입정렬의 연산시간
-. 연산시간 공식 : O(n²)
-. 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
-. 수학식으로 표현하면 아래와 같다.
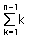 = n(n – 1) – (n – 1)/2 = n(n - 1)/2 이므로 Worst Case는 n(n – 1)/2 이다.
= n(n – 1) – (n – 1)/2 = n(n - 1)/2 이므로 Worst Case는 n(n – 1)/2 이다.
그래서 연산시간은 O(n²)가 되는 것이다.
5. 삽입정렬의 장점
-. 정렬된 값은 교환이 한번도 일어나지 않고 비교만 n- 1번 하게 된다. (그래서 속도가 빠르다.)
6. 삽입정렬의 단점
-. 입력자료(정렬되어 있는 자료인지 아니면 역순의 자료인지)에 민감하다.
-. 역순일 때는 교환과 비교의 회수가 N(N – 1)/2번이 되는 최악의 경우이므로 선택정렬보다
속도가 떨어진다.
버블 정렬
1) 버블정렬이란?
- 인접해 있는 두개의 값을 비교해서 자료 교환을 한다.
- 오름차순 정렬은 두 개의 값을 비교해서 큰 값을 오른쪽으로 보내는 방식이고, 내림차순 정렬은
두 개의 값을 비교해서 작은 값을 오른쪽으로 보내는 방식이다
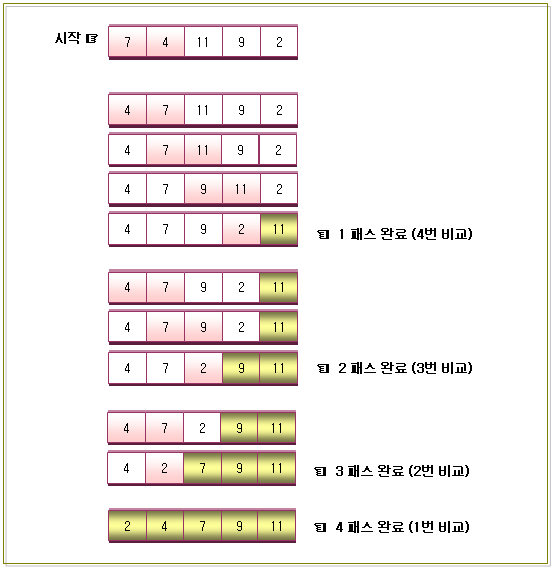
- 비교 회수 공식 : N(N – 1)/2
- 위의 그림을 보시면 아시겠지만 제일 처음에는 (N – 1)번을 비교하고, 그 다음에는 (N – 2)번
만큼 비교하고, 그 다음은 (N – 3)번을 비교하면서 비교회수가 1이 될 때까지 이 작업을 반복
할 것이다.
- 비교회수는 (N – 1) + (N – 2) + (N – 3) …… + 1 이 될 것이다. 최대 (N – 1)번을 수행할 것이
며, 각 패스가 수행할 때마다
2) 버블정렬의 연산시간
- 연산시간 공식 : O(n²)
- 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
3) 버블정렬의 장점
- 인접해 있는 두 개의 값을 비교하여 자료의 위치를 이동시키므로 단순하다.
- 여러 차례 값을 비교하므로 안전성 있게 값을 정렬한다.
4) 버즐정렬의 단점
- 첫번째 패스에서 자료의 교환이 없었다면 주어진 값은 이미 오름차순으로 정렬된 상태이지만,
최대 N(N – 1)/2 만큼의 비교회수와 O(n²) 만큼의 연산시간이 소요된다.
- 다른 정렬에 비해서 연산시간이 오래 걸린다.